0. イントロ
近年、深層学習をはじめとする機械学習モデルは劇的な進化を遂げていますが、その背後には従来の統計学では説明しきれない「謎」が存在していました。
従来の機械学習の汎化に関する理論(Rademacher complexity や VC dimension などの統計的学習理論)に基づくバイアス-バリアンス・トレードオフの常識では、パラメータ数がデータ数を上回る「過剰パラメーター領域」において、モデルは過学習を起こして未知のデータへの予測精度(汎化性能)が著しく悪化すると思われていました。 しかし2010年代後半以降、過剰パラメーター領域において、一度悪化した汎化性能が再び向上するという、従来の予測に反する現象が多くのモデルで確認されるようになりました。これが 二重降下現象(Double Descent) です。

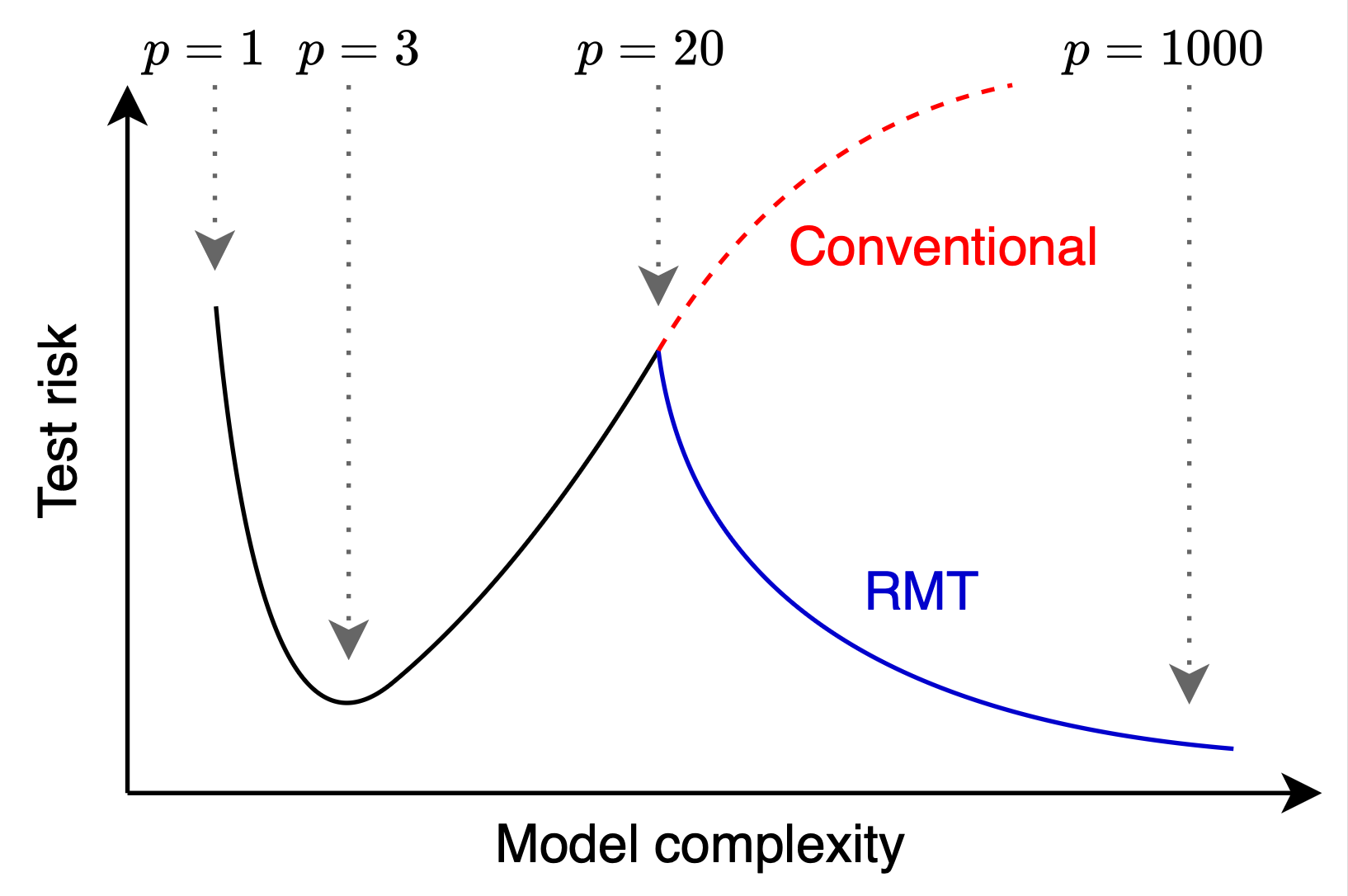
この不思議な現象を理論的に解き明かし、現代の高次元統計学や機械学習における新しい理論的基盤として脚光を浴びているのが、「ランダム行列理論(Random Matrix Theory: RMT)」 という数学・統計学の一分野です。
ランダム行列理論(RMT)とは?
そもそもランダム行列理論とは、その名の通り「行列の要素が確率変数であるような行列」の性質を研究する分野です。
例えば、各要素が独立で平均 0、分散 1 の正規分布(ガウス分布)に従う の行列 を生成すると、毎回異なる以下のような行列が得られます。
20世紀初頭に統計学の Wishart や原子核物理学の Wigner らによって創始されたこの理論は、「一見ランダムに見える要素の集まりから、行列のサイズ(次元)を無限大に近づけると、美しく決定論的な法則が立ち現れる」という驚くべき性質を持っています。
ランダム行列理論は、1920年代の多変量統計学(Wishart による共分散行列の研究)や、1950年代の量子力学に起源を持ちます。物理学者 Eugene Wigner は、重い原子核の複雑なエネルギー準位をモデル化するために、次のようなランダムな対称行列 を考えました。
驚くべきことに、この行列の次元 を無限大に近づけると、その固有値のヒストグラムは完全に決定論的な「半円」を描くことが証明されました。これを Wignerの半円則(Semicircle Law) と呼びます。 ランダムな要素の集まりから、完全に決定論的で美しい法則が立ち現れる。これが RMT の魅力の一端です。
import numpy as np
import matplotlib.pyplot as plt
# Wignerの半円則(GOE)のシミュレーション
n = 1000
A = np.random.randn(n, n)
GOE = (A + A.T) / np.sqrt(2 * n) # 対称化
eigvals_GOE = np.linalg.eigvalsh(GOE)
plt.hist(eigvals_GOE, bins=50, density=True, color="skyblue", edgecolor="black")
plt.title("Eigenvalues of GOE (Wigner Semicircle)")
plt.show()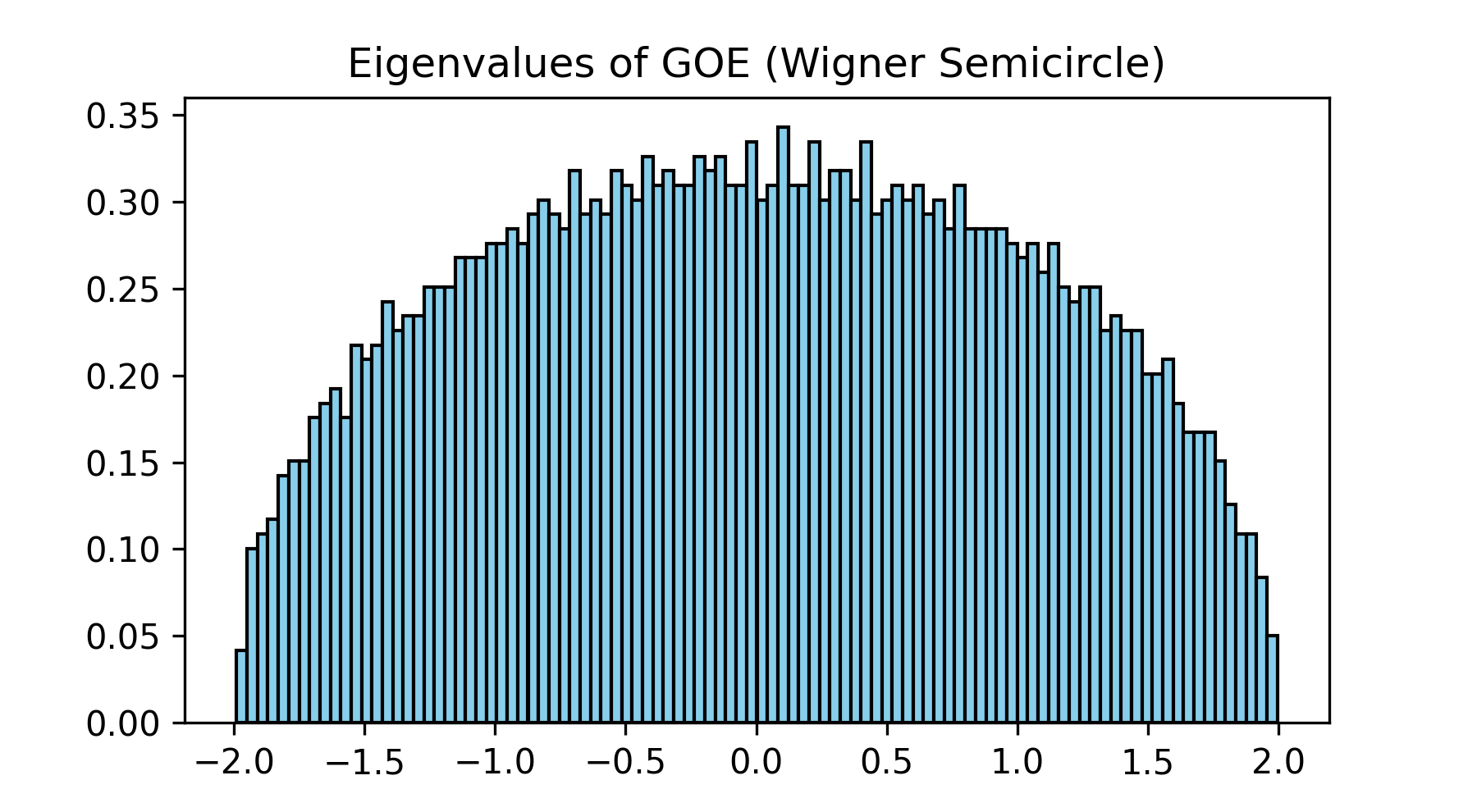
なぜ RMT が機械学習の謎を解けたのか?
では、なぜこの数学理論が、機械学習の汎化性能の解析に不可欠なツールとなったのでしょうか? それは、機械学習で扱う「データセット」やニューラルネットワークの「重みパラメータ」を、巨大なランダム行列として見立てることができるからです。
違いを端的にいうと、従来の統計的学習理論が「どんなに運が悪いデータが来ても、これ以上の誤差は出ない」という最悪のケースを想定して汎化誤差の上界を得る(Worst-case analysis)のに対して、RMT は確率的な極限を用いることで汎化誤差の「平均的な振る舞い」を記述することができます(Average-case analysis)。 そのため、RMT を使って導かれた汎化誤差の理論式は、過剰パラメータ領域における二重降下現象を見事に、かつ数学的に厳密に説明したのです。
本記事のロードマップ
本記事では、このランダム行列理論がいかにして進化し、現代の機械学習の基盤となったのか、その歴史的進展と理論的ブレイクスルーを以下の流れでわかりやすく解説します。
- 独立性の時代:Marchenko-Pastur 則 (1967)
- 制約の打破:Silverstein による強固な理論的基盤の確立 (1995)
- 決定論的等価性(Deterministic Equivalent)の確立 (2007-2011):Hachem & Loubaton & Najim (2007) と Rubio & Mestre (2011) による画期的なパラダイムシフト
- 非線形な特徴量ベクトルへの拡張 (近年):Louart らなどによる非線形な相関を持つデータへの理論的拡張
- テストリスクの解析と「二重降下現象」の解明:RMT はいかにして機械学習の謎を解き明かしたか
それでは、ランダム行列理論の奥深い世界へと足を踏み入れていきましょう。
1. サンプル共分散行列と Stieltjes(スティルチェス)変換
高次元データ解析における主要な研究対象は サンプル共分散行列(Sample Covariance Matrix)です。
個のサンプルと 個の特徴量を持つデータ行列を
としたとき、サンプル共分散行列は以下のように定義されます。
この行列 は、データの分散構造を表す重要な行列であり、機械学習モデルの訓練や性能評価において中心的な役割を果たします。 RMT において最も関心があるのは、行列の次元 が大きくなったときの固有値の分布です。 の 個の固有値を としたとき、その経験スペクトル分布(Empirical Spectral Distribution; ESD)は次のように書けます。
しかし、巨大なランダム行列の固有値を直接計算し、その分布関数を数学的に求めることは極めて困難です。そこでRMTの発展を支えることになった強力な解析ツールが Stieltjes(スティルチェス)変換です。 確率測度 に対する Stieltjes 変換 は、複素数 に対して以下で定義されます。
この定義を、サンプル共分散行列の経験スペクトル分布 に適用すると、驚くほどシンプルな行列の形に書き直すことができます。
この は レゾルベント行列(Resolvent Matrix) と呼ばれます。 RMT では、「直接、固有値を計算する」という困難なアプローチを捨て、「レゾルベントのトレースの極限(Stieltjes 変換)を求め、そこから複素解析的な手法を用いて固有値分布を逆算する」という洗練されたルートを辿ります。さらに言えば、リッジ回帰などの機械学習モデルのテスト誤差を評価する際、数式の中に直接このレゾルベントのトレースが現れるため、Stieltjes 変換を求めること自体が機械学習の性能予測に直結するのです。
2. 独立性の時代:Marchenko-Pastur 則 (1967)
従来の古典的な統計学では、特徴量数 が固定されたままサンプル数 となる極限を考えます。この場合、大数の法則により の固有値分布は、母共分散行列 の固有値に単に収束します。
しかし、現代の機械学習では、特徴量数 とサンプル数 が同程度の大きさであることが一般的です。実は、このような状況では、従来の統計学の理論は適用できず、母共分散行列 が単位行列 (すべての固有値が )の場合であっても、 の固有値分布は幅を持つ非自明な分布に収束します。
1967年、Marchenko と Pastur は、行列の次元 とサンプル数 が共に無限大に向かい、その比 が一定に保たれる「比例漸近領域(Proportional asymptotic regime)」において、この行列の固有値分布が決定論的な極限分布に収束することを示しました。
行列 の全成分 が互いに独立同分布(i.i.d.)であり、平均 、分散 に従うとする。すなわち、すべての は独立で、 とする。 このとき、 で となる極限において、 の経験的スペクトル分布は確率 で以下の密度関数 を持つ分布に弱収束する。
ここで
(Original paper: Distribution of eigenvalues for some sets of random matrices)
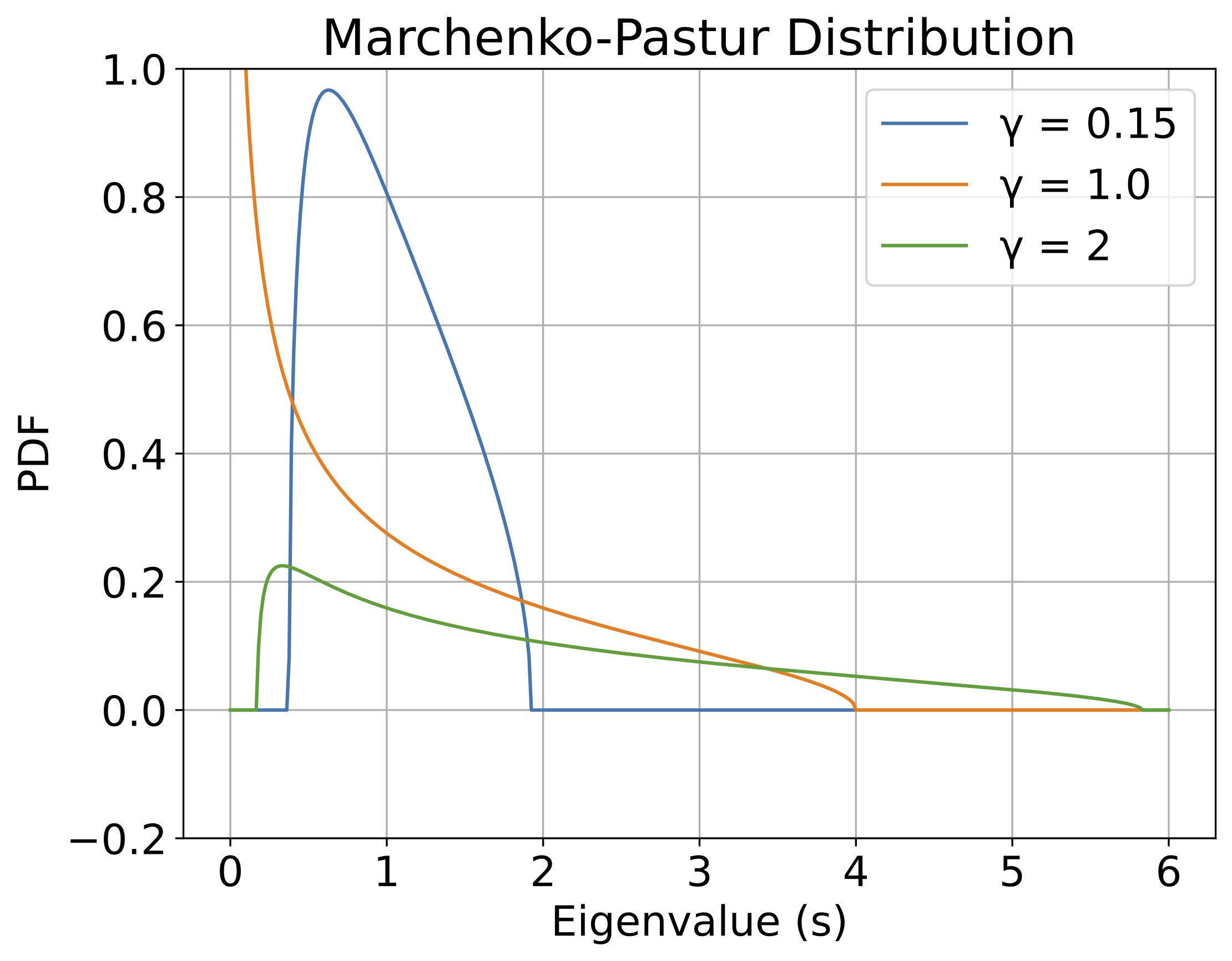
ここで注目すべきは、次元比率 (パラメータ数とサンプル数の比) による分布の変化です。
- (Under-parameterized): であり、固有値のバルクはゼロから離れた場所に綺麗な山を作ります。
- (Interpolation threshold): であり、 となるため、分布がゼロ付近で無限大に発散する特異点(ピーク) が生まれます。行列の最小固有値がゼロに近づき、極めて悪条件(ill-conditioned)になることを意味します。これが後述する「二重降下の補間ピーク(エラーの発散)」の直接的な原因です。
- (Over-parameterized): となり、行列がランク落ちを起こします。その結果、厳密にゼロの固有値が大量に発生(数式第2項のデルタ関数 )し、残りのゼロでない固有値は右側にバルクを形成します。
この結果は極めて強力でしたが、「全成分が完全に独立である(母共分散行列 )」という強い仮定 に基づいていました。現実のデータは、特徴量間に複雑な相関構造を持つことが一般的であり、この独立性の仮定は実践的な機械学習モデルの性能解析には適用できませんでした。
Marchenko-Pastur 則を含む RMT の結果が機械学習において絶大な実用性を誇る理由は、普遍性(Universality) という性質にあります。データ行列の要素が、綺麗な「ガウス分布(正規分布)」から生成されていても、単に と が等確率で出る「コイントス(Rademacher 分布)」から生成されていても、平均と分散(2次までのモーメント)さえ一致していれば、極限における固有値分布は全く同じ Marchenko-Pastur 則のカーブにピタリと重なります。 データの細かな分布形状(高次のモーメント)に依存しないからこそ、理論的な数式が現実のデータに対しても強い予測力を持つのです。
# Wishart行列(Marchenko-Pastur則)のシミュレーション
p, N_s = 500, 1000 # γ = 0.5 のケース
X = np.random.randn(p, N_s)
W = np.dot(X, X.T) / N_s
eigvals_W = np.linalg.eigvalsh(W)
# コイントス(Rademacher分布)でのシミュレーション
X_rademacher = np.random.choice([-1, 1], size=(p, N_s))
W_rademacher = np.dot(X_rademacher, X_rademacher.T) / N_s
eigvals_W_rademacher = np.linalg.eigvalsh(W_rademacher)
plt.hist(eigvals_W, bins=50, density=True, alpha=0.6, label="Gaussian")
plt.hist(eigvals_W_rademacher, bins=50, density=True, alpha=0.6, label="Rademacher (Coin Toss)")
plt.title("Universality of Marchenko-Pastur Law")
plt.legend()
plt.show()
# 有限の実験でも共にほぼ同じ分布に収束することがわかる(極限においては完全に同一の分布)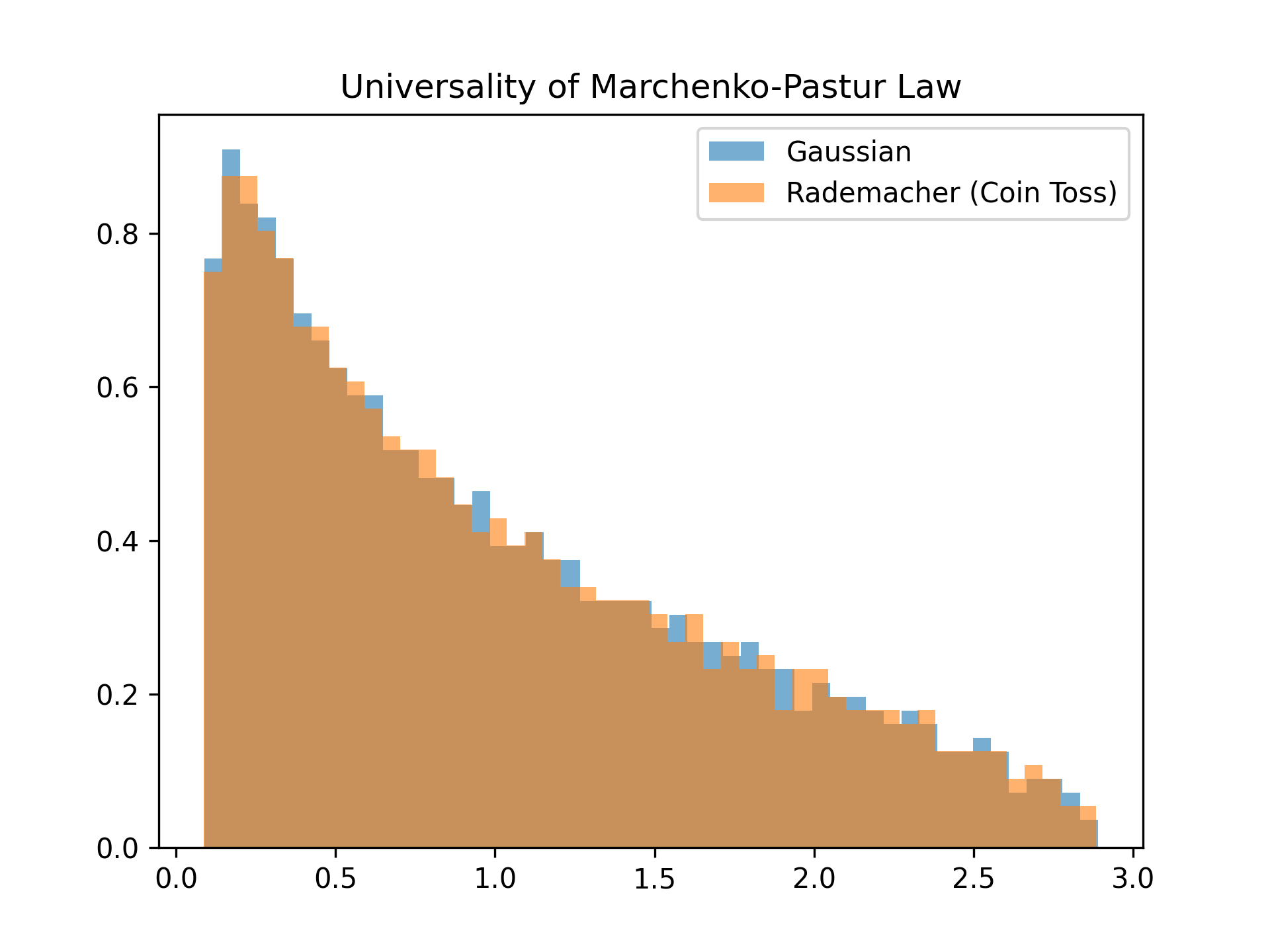
3. 制約の打破:Silverstein による強固な理論的基盤の確立 (1995)
第2章で紹介した標準的な Marchenko-Pastur 則は非常に美しく強力ですが、「すべての特徴量が完全に独立である(真の母共分散行列 )」というケースによく適用されます。しかし、現実の画像データや音声データでは、ピクセル間や特徴量間に複雑な相関が存在するため、独立性の仮定は実践的な機械学習モデルの解析には適用できません。
実は、1967年の Marchenko と Pastur の原論文において、すでにデータの相関構造を考慮したケースの方程式の原型自体は示されていました。しかし、その数学的な証明には「行列要素の絶対4次モーメントが有限であること」など、現実のデータに適用するには厳しすぎる制約が課されていました。
この理論的な壁を打ち破り、現代の機械学習へつながる強固な基盤を完成させたのが、1995年の数学者 Jack Silverstein の研究です。彼はデータ行列 が、真の共分散行列 を用いて次のように生成される設定を考えました。
ここで、 は各要素が i.i.d. (独立同分布)であるノイズ行列です。このとき、サンプル共分散行列は と書けます。( を固定して の極限では、 は単位行列 に収束するため、 の固有値分布は の固有値分布に収束します。)
Silverstein の最大の功績は、 次モーメントなどの厳しい制約を完全に取り払い、「ノイズ行列 の各要素が平均 ・分散 ( 次モーメント)さえ持てばよい」という最小限の仮定のもとで定理を証明したことです。 具体的には、(比率 )となり、かつ真の共分散行列 の経験固有値分布がある極限分布 に収束するという自然な高次元極限において、 のスペクトル分布が確率 で決定論的な極限分布に収束する(概収束:Strong Convergence)ことを厳密に示しました。
そして、その極限における Stieltjes 変換 が、以下の積分方程式の唯一の解になることを証明したのです。
この結果の凄みは、「成分の完全な独立性を捨て、真の相関構造を極限分布 として理論に組み込めるようにしたこと」にあります。極端な外れ値を持つような厄介なデータであっても、分散さえ定義できれば、この自己無撞着方程式を通じて固有値分布の極限の姿を捉えることが保証されたのです。
しかし、実務家や機械学習エンジニアにとって、この抽象的な「積分形」の方程式を直接計算機に乗せ、モデルの性能予測に使うにはまだ壁がありました。極限分布 の解析的な形が未知であることが多いからです。
とはいえ、Silverstein がここで築き上げたランダム行列の極限の振る舞いを、真の相関構造に基づく方程式で厳密に記述できるという事実は、2000年代の研究者たちに極めて重要なインスピレーションを与えます。 やがてこの積分方程式のアイデアは、有限次元の行列 をそのまま使った「実用的なトレース形の方程式」へと再構築され、次章で解説する「決定論的等価性(Deterministic Equivalent)」という強力なパラダイムシフトへと一直線に繋がっていくことになります。
- Silverstein, J. W. (1995). Strong convergence of the empirical distribution of eigenvalues of large dimensional random matrices.
4. 決定論的等価性(Deterministic Equivalent)の導入 (2007-2011)
Silversteinの研究により、相関を持つデータから作られたサンプル共分散行列の「トレース(固有値の総和に関わる量)」は計算できるようになりました。しかし、実際の機械学習アルゴリズムの解析には、これでは不十分でした。
例えば、線形回帰に正則化を加えた リッジ回帰(Ridge Regression) を考えてみましょう:
訓練データ とターゲット変数 から最適なパラメータベクトル を求める解は、以下のような閉形式(Closed-form)で与えられます。
このパラメータを使って新しい未知のデータに対する「テスト誤差(汎化誤差)」を計算しようとすると、単なる Stieltjes 変換: だけでなく、例えば、
といった、より複雑な項が現れてしまいます。これらの項は、単なるトレースの極限を求めるだけでは解析できませんでした。
この壁を打ち破ったのが、2007年の Walid Hachem ら、および 2011年の Fernando Rubio と Xavier Mestre らによる 「決定論的等価性(Deterministic Equivalent: DE)」 という画期的なパラダイムです。
- DETERMINISTIC EQUIVALENTS FOR CERTAIN FUNCTIONALS OF LARGE RANDOM MATRICES by Walid Hachem, Philippe Loubaton and Jamal Najim (2007)
- Spectral Convergence for a General Class of Random Matrices by Fernando Rubio and Xavier Mestre (2011)
彼らは、トレースの極限だけでなく、「巨大なランダム行列の逆行列それ自体」を、数学的に扱いやすい非確率的(決定論的)な行列に置き換えられることを証明しました。
ランダム行列の系列 と決定論的(ランダムでない)な行列の系列 について、スペクトルノルムが有界()である任意の決定論的行列 に対して、
が成り立つとき、 ( は の決定論的等価物である)と表記します。 これにより、複雑なランダム行列の極限での挙動を、扱いやすい決定論的(すなわちランダムでない)な行列の計算に置き換えることができます。
2011年、Rubio と Mestre は、相関を持つデータ について、リッジ回帰の解の中心となるレゾルベントの決定論的等価物を以下の公式として導き出しました。
TODO: Add precise assumptions and conditions for the theorem.
データ行列が で与えられるとき、 で となる極限において、以下が成り立つ。
ここで、有効正則化パラメータ は、以下の 自己無撞着方程式(Self-consistent equation) の唯一の解である。
(Original paper: Spectral Convergence for a General Class of Random Matrices)
【なぜこれがすごいのか?】 リッジ回帰の予測誤差を計算しようとすると、どうしても数式の中に というランダム行列の逆行列が登場してしまい、解析が行き詰まります。 しかし、この「決定論的等価物」の公式を適用すれば、ランダムな を一瞬にして真の とスカラー に置き換えることができ、高次元データにおける機械学習アルゴリズムの真の性能(汎化誤差など)を紙とペンで正確に計算できるようになるのです。
5. 非線形の最前線へ
Rubio & Mestre の理論は圧倒的でしたが、致命的な弱点がありました。それは「データの生成過程が線形()でなければならない」という点です。 現代の機械学習、例えば Generative Adversarial Networks (GANs) のジェネレータやランダム特徴量モデル(Random Feature Models)などは、データを極めて高度な非線形関数で変換します。線形性の仮定は、ここには全く通用しません。
しかし、近年の研究がこの壁を破壊しました。例えば、Louart らは、データがリプシッツ連続な非線形関数を通して生成される「集中特徴ベクトル(Concentrated Feature Vectors)」であっても、Rubio & Mestre の定理(線形の決定論的等価物)が全くそのまま適用できることを証明したのです(最近、これよりさらに緩和した条件でも同様の結果が得られることが示されました)。 これが「古典的な RMT」と「現代の複雑な非線形モデルによる機械学習」を繋ぐ架け橋となりました。
潜在変数 とリプシッツ連続(Lipschitz continuous)な非線形関数 を通して、特徴ベクトルが の形で生成されるとします。このように生成される特徴ベクトルを「集中特徴ベクトル(Concentrated Feature Vectors)」と呼びます。
TODO: Add precise assumptions and conditions for the theorem.
データ が上記のリプシッツ連続な関数により生成されると仮定し、その母共分散行列を とする。このとき、 で となる極限において、リゾルベントの決定論的等価物は以下のように与えられる。
ここで は、以下の方程式の唯一の非負の解である。
高度に非線形な特徴量であっても、極限においては Rubio & Mestre と全く同じ決定論的等価物が成立することは、RMTの普遍性(Universality) を強力に裏付ける結果です。
- 2018: A Random Matrix Approach to Neural Networks
- 2023: Spectral properties of sample covariance matrices arising from random matrices with independent non identically distributed columns
- 2026: Resolvent convergence for sample covariance matrices with general covariance profiles and quadratic-form control
6. テストリスクの解析と「二重降下現象」の解明
決定論的等価性(DE)という最強の武器を手に入れたことで、私たちはリッジ回帰などの機械学習モデルの テストリスク(未学習データに対する予測誤差の期待値) を厳密に計算することが可能になりました。
テストリスク は、予測モデルのバイアス(Bias)、分散(Variance)、および観測不可能なノイズ()の3つの項に分解されます。この式にRubio & Mestreの定理と複素解析の手法を適用すると、以下の定理が得られます。
TODO: Add precise assumptions and conditions for the theorem.
で となる極限において、リッジ回帰のテストリスク は以下の決定論的等価物 に漸近する。
ここで は「正規化された有効自由度(normalized effective degrees of freedom)」である。
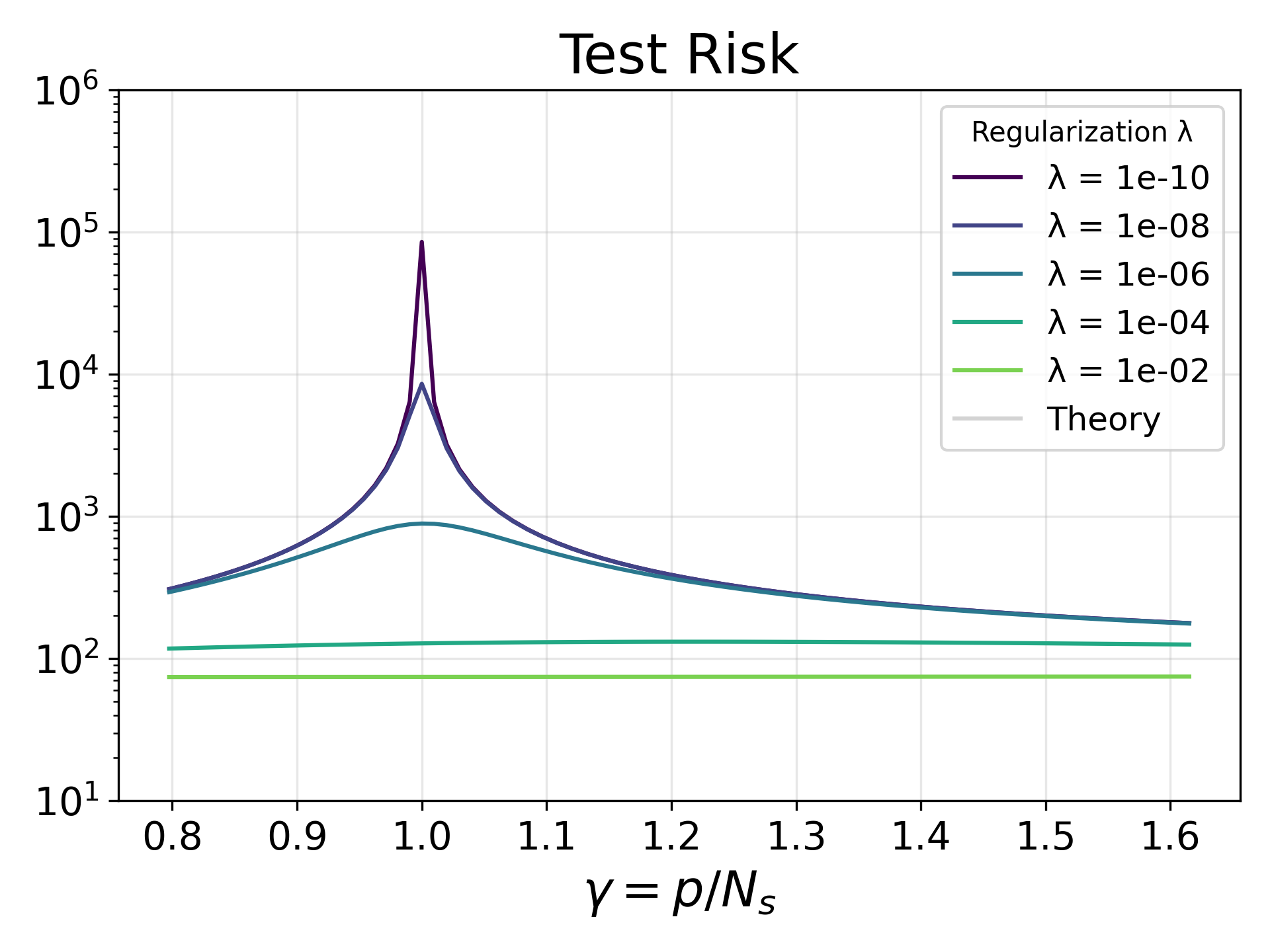
この数式こそが、「二重降下現象(Double Descent)」 がなぜ起こるのかを数学的に完全に説明します。
第2章の Marchenko-Pastur 則で、次元比率 が (つまりパラメータ数とサンプル数が等しい)のとき、固有値分布のゼロ付近に無限大のピークができる(行列が極めて悪条件になる)ことを確認しました。
Theorem 3 の数式を見ると、正則化 かつパラメータ数がサンプル数に近づく()とき、有効自由度 が に近づきます。 すると、バリアンス項の分母 がゼロに近づき、バリアンス(ノイズへの過敏性)が無限大に爆発してしまいます。 行列の悪条件化が、数式上でテストリスクの発散(補間ピーク:Interpolation peak)としてハッキリと現れるのです。
しかし、パラメータ数をさらに増やして過剰パラメータ領域()に突入すると、再び が から離れ、モデルの表現力が上がって良条件な部分空間で最適化が進むため、テストリスクは再び減少していきます。これが二重降下のメカニズムです。
7. RMTの実用的な価値:モデル訓練をスキップした性能予測
この Theorem 3 の結果は、理論的に美しいだけでなく極めて実用的な価値を持っています。
従来、機械学習モデルの汎化性能を評価するためには、大量のデータセットを生成し、何度もモデルの訓練(行列の逆行列計算や最適化ループ)を繰り返し、テストエラーの平均を経験的に計算する必要がありました。これは計算リソースの観点で非常に高コストです。
しかし、この漸近的テストリスクの公式 を用いれば、モデルの訓練プロセスを完全にスキップできます。対象データの「母共分散行列 」と「ターゲットベクトル 」のスペクトル情報を自己無撞着方程式に代入するだけで、あらゆるデータサイズ や正則化パラメータ に対するテストリスクのカーブを瞬時に、かつ解析的に描き出すことができるのです。
を前提とした理論でありながら、有限で小規模なシステムにおいても、RMTによる理論予測曲線が経験的なテストエラーと驚くほど正確に一致することが実証されています。
8. 自由確率論と最適化ダイナミクスへの応用
RMTの恩恵は、訓練が終わった後の汎化性能(Generalization)の予測だけにとどまりません。実は、勾配降下法(Gradient Descent: GD)などの 最適化アルゴリズムが、学習ステップごとにどのように収束していくか(学習ダイナミクス) の解析にも劇的な効果をもたらします。
機械学習のモデル学習において、損失関数がどのような形状の谷(Loss Landscape)をしているかを決定するのは、二階微分であるヘシアン(Hessian)行列 です。 ニューラルネットワークのヘシアンは、しばしば「データが持つ構造項 」と「サンプリングによるノイズ項 」の足し算 としてモデル化されます。
ここで大きな問題が生じます。行列の掛け算は非可換()であるため、通常の確率変数の足し算で使う「畳み込み積分」を使って、複数のランダム行列を足し合わせた後の固有値分布を計算することはできません。 これを解決するのが、RMT における 自由確率論(Free Probability Theory) です。
ランダム行列の次元が無限大に向かうとき、行列の固有ベクトル同士の向きが互いに完全にランダム(無相関)になる性質を 漸近的自由性(Asymptotic Freeness) と呼びます。 この性質が成り立つとき、-変換(R-Transform) という特別な関数を使うことで、 と の固有値分布を直接足し合わせて、 の固有値分布を厳密に計算することができます。(これは、通常の確率変数における特性関数やラプラス変換が行列に拡張されたようなイメージです)。
このヘシアンのスペクトル解析により、最悪のケース(Worst-case)ではなく、平均的なケース(Average-case) におけるアルゴリズムの性能評価が可能になります。「勾配降下法が何ステップでどれくらい誤差を減らすか(Halting time)」や、「最速で学習を終わらせるための最適な学習率(ステップサイズ)」までも、RMTの理論式から事前に導き出すことができるのです。
9. まとめ
ランダム行列理論は、単純なノイズ行列の固有値分布の解析(Marchenko-Pastur 則)から始まりました。その後、Silverstein らによって現実的な相関構造()が取り入れられて、Stieltjes変換という解析的ツールが磨かれ、Hachemら や Rubio、Mestre らによって決定論的等価性(Deterministic Equivalent)という強力なパラダイムが確立されました。現在も、Louart らによる非線形な特徴量への拡張など、RMTの理論は日々進化を続けています。
現在、ランダム行列理論は純粋数学や物理学の枠を超え、深層学習のダイナミクス解析や汎化性能の解明において最も強力な理論的武器の一つとして活躍しています。
References
- Marčenko, V. A., & Pastur, L. A. (1967). Distribution of eigenvalues for some sets of random matrices.
- Silverstein, J. W. (1995). Strong convergence of the empirical distribution of eigenvalues of large dimensional random matrices.
- Hachem, W., Loubaton, P., & Najim, J. (2007). Deterministic equivalents for certain functionals of large random matrices.
- Rubio, F., & Mestre, X. (2011). Spectral convergence for a general class of random matrices.
- Louart, C., Liao, Z., & Couillet, R. (2018). A random matrix approach to neural networks.
- Louart, C., & Couillet, R. (2023). Spectral properties of sample covariance matrices arising from random matrices with independent non identically distributed columns.
- Random Matrix Theory and Machine Learning Tutorial